IGV
Last updated on 2025-12-22 | Edit this page
Estimated time: 60 minutes
Overview
Questions
- How do you use IGV?
Objectives
- Learn how to open basic file types and navigate IGV
- Understand the type of data that can be visualised in IGV
IGV
In this section we will download a BAM file of gene expression data from SRA, and view it in the Integrated Genome Viewer (IGV). BAM files must first be sorted and indexed before they can be loaded into genome viewers. IGV has tools to do this without having to use the command line.
Exercise
The data
The expression data we are using for this exercise is from the mouse Celltax single cell expression atlas published by the Allen Brain Institute. The cell tax vignette has an expression browser that displays gene level expression as a heat map for any gene of interest. The readsets (fastq files) and aligned data (BAM files) for 1809 runs on single cells are also available for download from SRA.
The SRA study ID for this study is SRP061902 and individual runs from this study are easily selected by viewing the samples in the ‘RunSelector’.
For this exercise, we will download a few samples in order to illustrate navigating in IGV by looking at the expression of NTRK2 in the same cell types we have discussed in earlier exercises. For each cell type, we will down load a .BAM file containing only the reads from the chromosome of interest.
Your task
1. Download BAM files from SRA
For each SRA run in the table below:
Click on the SRA run to open the link.
Click on the ‘Alignment’ tab. Note that the data is aligned to the mouse GRCm38 genome (mm10).
Select the chromosome of interest. For Ntrk2 in mouse it is chr13
For
Output this run in:selectBAMand click onformat to: FileRename the downloaded file to include the cell type, to avoid confusion, e.g. SRR2138661_astrocyte_chr13.bam
| Cell type | SRA run | Vignette Cell ID |
|---|---|---|
| astrocyte | SRR2138962 | D1319_V |
| astrocyte | SRR2139935 | A1643_VL |
| neuron | SRR2139989 | S467_V4 |
| neuron | SRR2140047 | S1282_V |
2. Use IGV tools to SORT and INDEX the BAM files
Open IGV and select
Tools > Run igvtoolsfrom the pull down menusSelect
Sortfrom the Command options and use the browse options to select the BAM file you just downloaded. ClickRunWithout closing the igvtools window, now select the command
Indexand browse to find the BAM file you just sorted. It will have the same file name with ‘sorted’ added to the end, e.g. SRR2138661_astrocyte_chr13.sorted.bam
The resulting index file will have the file name SRR2138661_astrocyte_chr13.sorted.bam.bai
IMPORTANT
It is essential that the index file for a BAM file has the same name and is located in the same folder as its BAM file. If not, the IGV software will not be able to open the BAM file.
3. View the BAM files in IGV
Select the Mouse (mm10) genome from the genome box in the top right hand corner.
Select
File > Load from Fileand select all four _chr13.sorted.bam files only.Select
open- but don’t expect to see any data yet. The genome view window opens on a whole chromosome view as default but it wont show any data until the view region is small enough to show all data in the current view.Type the gene name NTRK2 into the search window.
Expand the Refseq gene model track by right clicking it to see all the splice variants.
-
The gene and thus the genome view is 328kb and the default setting for viewing data is only 100kb. Unless you have already changed your settings, alignment data will not get be showing. Zoom into the region of a coding exon by selecting in the numbered location track at the top of the genome view.
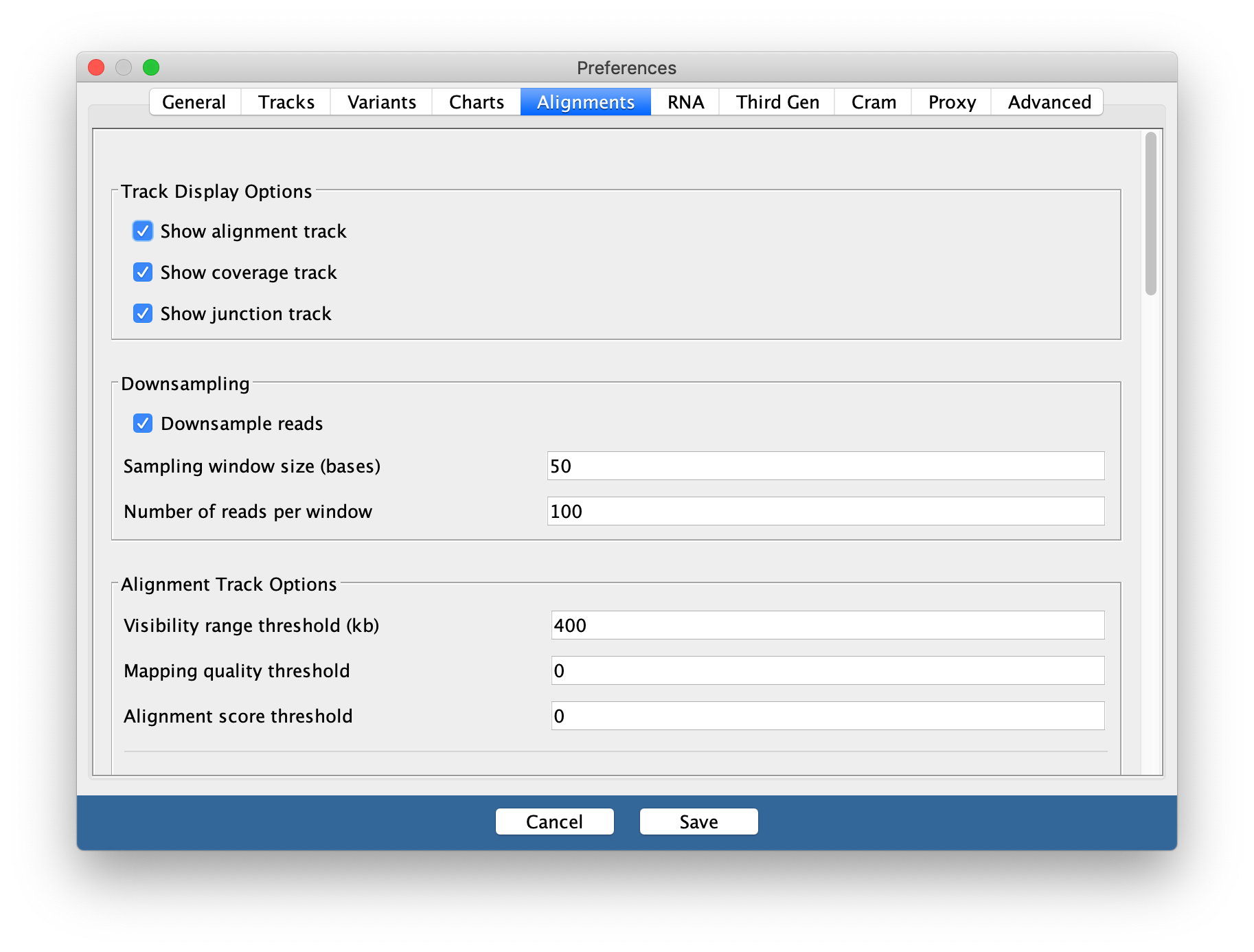
To see the whole gene in the genome window at the same time you may need to change the preferences.
Go to
View > Preferencesand select theAlignments tab. Change the visibility range threshold to 400kb.
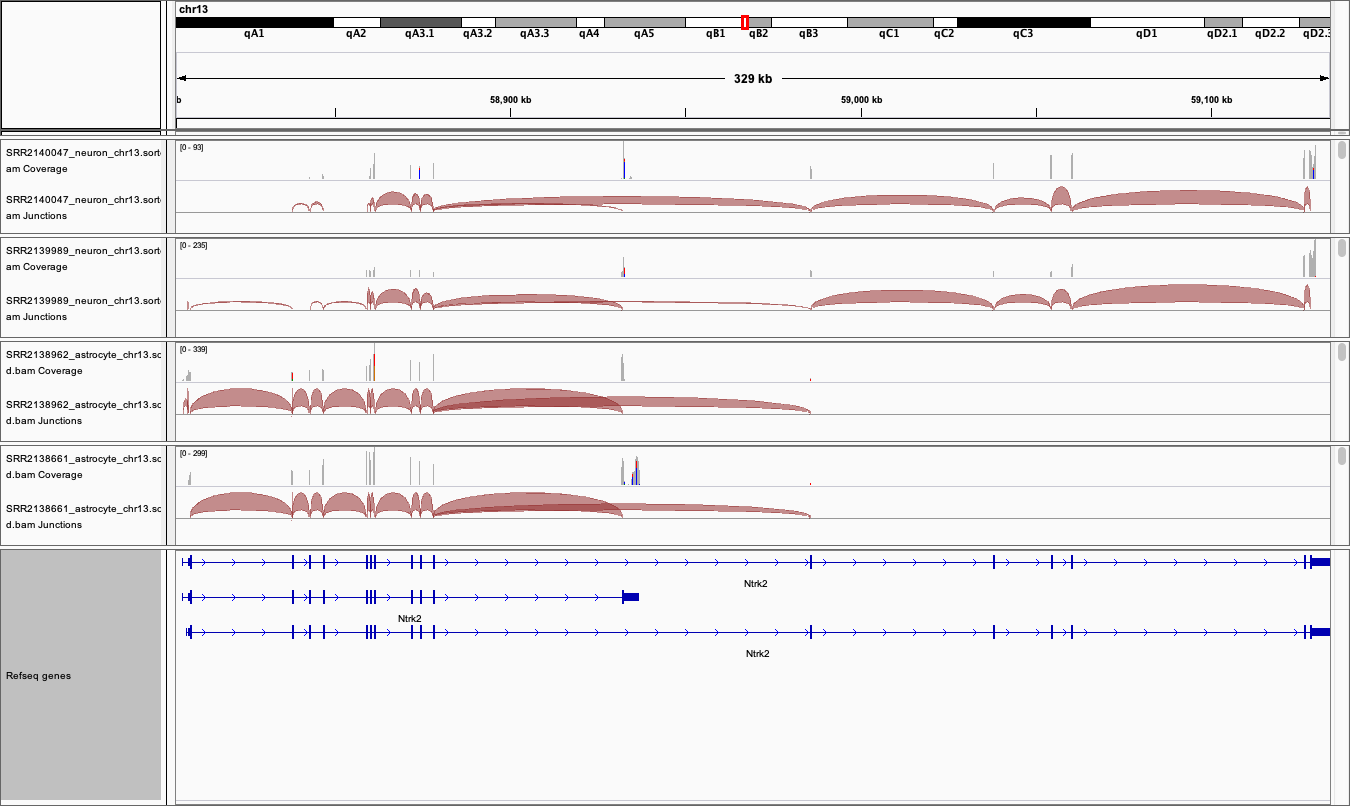
4. Export images
The Genome view above can be exported by selecting
File > Save imagefrom the tool bar-
To export the Sashimi plot below:
- Right click on one of the junction tracks and select
Sashimi Plotfrom the pull down menu. - Select the tracks you want in your final image.
- There are some data filtering and style adjustments you can make to the Sashimi plot. Right click on each track to access the menu options. Some changes apply to each track individually and some to all tracks.
- Right click on one of the junction tracks and select
5. Download and install the Gencode gene model annotation track
The refseq gene model track is not as comprehensive as GenCode gene models. For both Human and Mouse the Gencode gene model gtf annotation files can be downloaded from Gencode. If you wish to do this be aware that it takes a little time and is not done as part of a workshop.
Create a folder called ‘annotations/Mouse’ in the main ‘igv’ folder that was installed on your computer when you downloaded IGV.
Download the GTF file from the link above and save it in this folder.
Unpack and then sort and index the .gtf file using igvtools.
In IGV, before you load you data files, load this annotation file and it will replace the refseq one.
If you would like to learn more about how to use IGV, please go to:
https://rockefelleruniversity.github.io/IGV_course/presentations/singlepage/IGV.html
- IGV can sort and index BAM files without use of the command line
- Sorted and indexed BAM files can then be opened to view genomic sequencing and gene expression data in IGV